基本信息
案例ID:182671
技術(shù)顧問:hugh崔 - 9年經(jīng)驗(yàn) - 黑龍江省建工集團(tuán)

微信掃碼,建群溝通
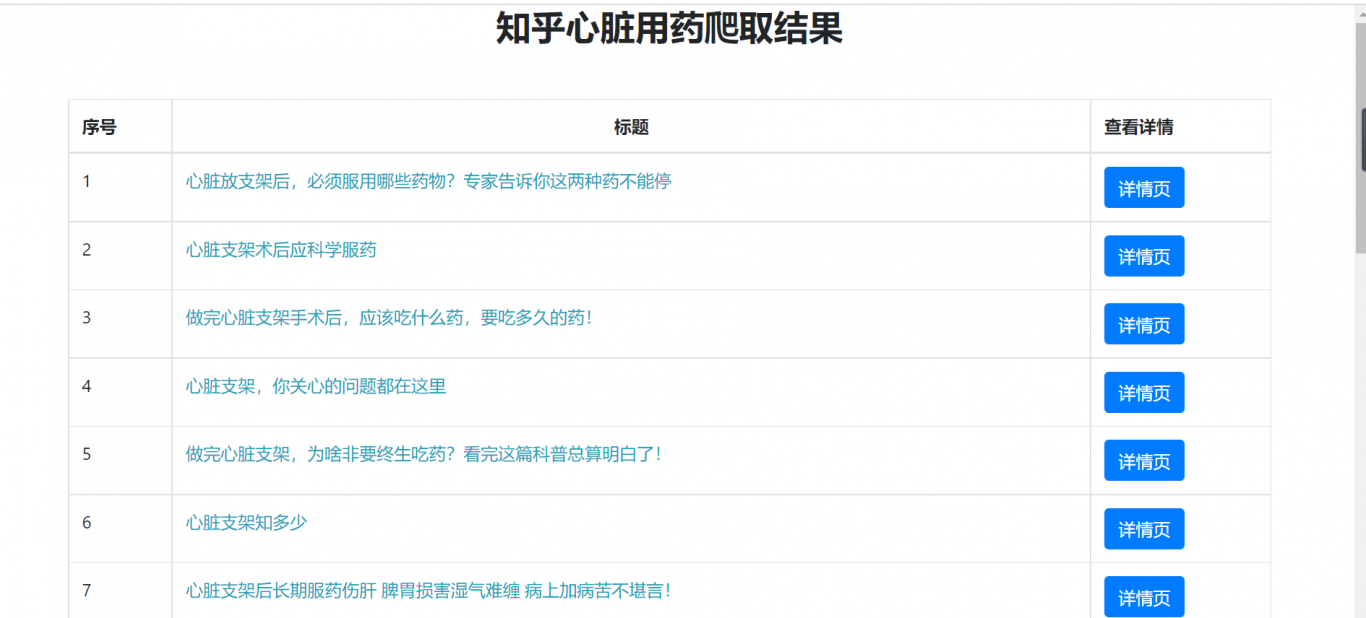
項(xiàng)目名稱:知乎心臟用藥爬取結(jié)果
所屬行業(yè):醫(yī)療健康 - 專業(yè)細(xì)分服務(wù)
->查看更多案例案例ID:182671
技術(shù)顧問:hugh崔 - 9年經(jīng)驗(yàn) - 黑龍江省建工集團(tuán)
項(xiàng)目名稱:知乎心臟用藥爬取結(jié)果
所屬行業(yè):醫(yī)療健康 - 專業(yè)細(xì)分服務(wù)
->查看更多案例
此作品對知乎的心臟用藥的相關(guān)結(jié)果做了一個總結(jié),一共10頁,每頁20條信息。我是開發(fā)者角色,其中我使用selenium的動態(tài)網(wǎng)頁爬取技術(shù)打開知乎網(wǎng)頁,然后又使用beautifulsoup進(jìn)行了頁面解析。然后我又使用了前端的vue框架和bootstrap的技術(shù)給獲取的信息進(jìn)行了分頁處理,在每個詳情頁又使用了js技術(shù)獲取下一條或者上一條信息和返回列表功能.
1. 通過webdriver實(shí)例化一個瀏覽器對象【谷歌瀏覽器】
2.遇到selenium能被知乎識別的反爬問題,使用自己打開的一個瀏覽器,繞開反爬
再用selenium接管這個瀏覽器這樣就可以完成反爬的處理。
3. 通過urllib模塊輸入相關(guān)問題,然后直接通過selenium,下拉網(wǎng)頁到最后
4. 通過beautifulsoup的語法獲取相關(guān)超鏈接和標(biāo)題
5. 通過requests模塊向這些超鏈接發(fā)送請求,然后獲取返回頁面的源碼后用xpath語法獲取需要的數(shù)據(jù),
然后存入mysql數(shù)據(jù)庫
6.建立前端的vue-cli腳手架,通過bootstrap和vue的相關(guān)指令生成前端頁面
7.通過pdo和數(shù)據(jù)庫連接返回所需的數(shù)據(jù),然后和vue框架進(jìn)行前后端的交互
8.將相關(guān)的vue框架和后端的php文件上傳到阿里云服務(wù)器

其他人才的相似案例推薦

我的職責(zé):負(fù)責(zé)個人中心頁面及功能,設(shè)備信息頁面及功能,sim
用")
負(fù)責(zé)的角色:前端開發(fā)工程師(獨(dú)立負(fù)責(zé)) 主要完成項(xiàng)目搭建、

這是幫一個門戶網(wǎng)站+產(chǎn)品平臺。門戶采用ssr做的服務(wù)端渲染,
")
一、樣本數(shù)據(jù)模塊 主要是通過網(wǎng)絡(luò)或者串口接收儀器端發(fā)送過來的
品")
女性健康類工具,為用戶提供生理健康自檢、健康報告匯總、生理檢

1.負(fù)責(zé)整套流程的搭建和部署。 2.服務(wù)部署的高可用。
據(jù)平臺")
作品詳情:統(tǒng)一公司系統(tǒng)公用數(shù)據(jù),避免數(shù)據(jù)重復(fù)治理與不一致;
")
作品功能: 1. 慢病購藥系統(tǒng)。 2. 包括藥品列表,藥

作品功能:小藥箱是一個H5應(yīng)用,把藥品組合成不同的套餐包的形
目")
隨著社會的發(fā)展,5G與VR技術(shù)的高速發(fā)展。VR視頻通過5G直
程醫(yī)療項(xiàng)目")
為實(shí)現(xiàn)醫(yī)療機(jī)構(gòu)的遠(yuǎn)程教學(xué)需求,產(chǎn)品面向醫(yī)療機(jī)構(gòu)客戶,提供集學(xué)

從環(huán)境污染方面所說的重金屬,實(shí)際上主要是指汞、鎘、鉛、鉻、砷
關(guān)注猿急送微信平臺,接收實(shí)時人才推送

